library(Rcrawler) # Package for web crawlingWarning: package 'Rcrawler' was built under R version 4.2.3Web crawling involves going through different links to gather up a bunch of links that are deemed relevant to the use case. Web crawling is a way to collect relevant links (URLs) from the internet.
library(Rcrawler) # Package for web crawlingWarning: package 'Rcrawler' was built under R version 4.2.3The package has many different functions. I will go through a few here that can be used to extract information and figure out which part of the webpage you would like to target for crawling. In this case, I use fortune.com as an example. We could, for example, be interested in the establishment of new enterprises working with artificial intelligence.
LinkExtractor to get an overview of the links in the webpage to understand which links I might want to start working from.page <- LinkExtractor(url = "https://fortune.com/", ExternalLInks=TRUE)
glimpse(page)List of 3
$ Info :List of 11
..$ Id : int 110
..$ Url : chr "https://fortune.com/"
..$ Crawl_status: chr "finished"
..$ Crawl_level : num 1
..$ SumLinks : num 236
..$ : chr ""
..$ Status_code : int 200
..$ Content_type: chr "text/html"
..$ Encoding : chr "utf-8"
..$ Source_page : chr "<!DOCTYPE html><html lang=\"en\"><head><meta charSet=\"utf-8\"/><meta name=\"viewport\" content=\"width=device-"| __truncated__
..$ Title : chr "Fortune - Fortune 500 Daily & Breaking Business News | Fortune"
$ InternalLinks: chr [1:223] "https://fortune.com/" "https://fortune.com/the-latest/" "https://fortune.com/section/tech/" "https://fortune.com/section/finance/" ...
$ ExternalLinks: chr [1:13] "https://order.emags.com/fortune_single_issues" "https://customcontentonline.com/" "https://fortuneconferences.com" "https://fortunemediakit.com/" ...I use ContentScraper to find out how to refer to the relevant parts of the webpage (i.e. which nodes I am interested in). Assuming I’m interested in the News tab on fortune.com, I check the output above and realize that this link is called https://fortune.com/the-latest. This will be the input to the Url argument in the function. In the XpathPatterns argument, I use the Xpath to the node, which I can find in just the same manner as the node, just click “Copy Xpath” instead of “Copy selector”. Like so:
Right-click on the node.
Choose “Copy”.
Choose “Copy XPath”.
Then I also have to add the names of the parent nodes to the Xpath. This is one div node and one ul1 node.
ContentScraper(Url = "https://fortune.com/the-latest",
XpathPatterns = "//div/ul[@class='termArchiveContentList']")[[1]]
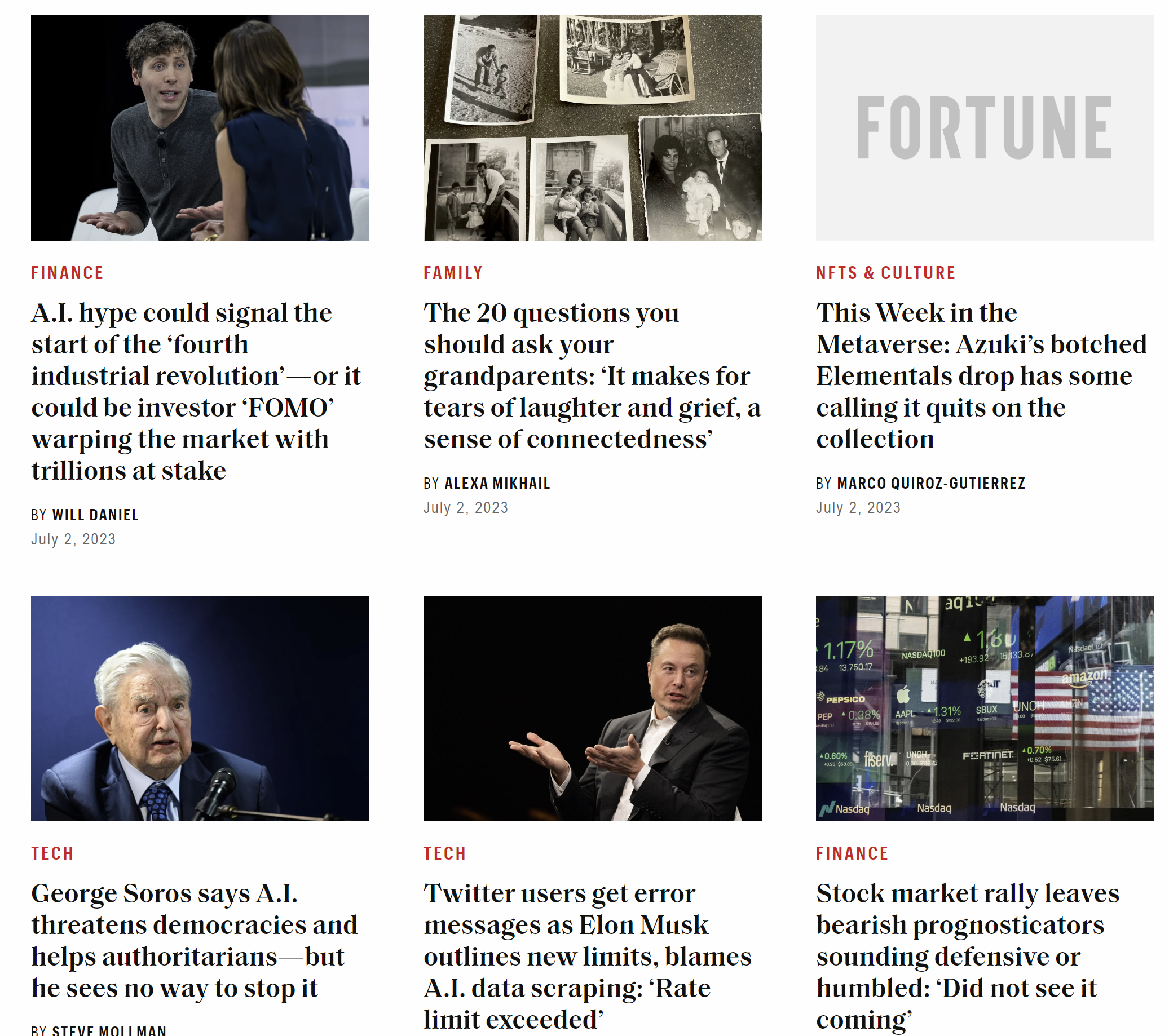
[1] "FinanceA.I. hype could signal the start of the ‘fourth industrial revolution’—or it could be investor ‘FOMO’ warping the market with trillions at stakeBYWill DanielFamilyThe 20 questions you should ask your grandparents: ‘It makes for tears of laughter and grief, a sense of connectedness’BYAlexa MikhailNFTs & CultureThis Week in the Metaverse: Azuki’s botched Elementals drop has some calling it quits on the collectionBYMarco Quiroz-GutierrezTechGeorge Soros says A.I. threatens democracies and helps authoritarians—but he sees no way to stop itBYSteve MollmanTechTwitter users get error messages as Elon Musk outlines new limits, blames A.I. data scraping: ‘Rate limit exceeded’BYSteve MollmanFinanceStock market rally leaves bearish prognosticators sounding defensive or humbled: ‘Did not see it coming’BYAlexandra Semenova and Bloomberg"You can see here how the headlines in the output above refers to the headline on the actual webpage.
Rcrawler function.Rcrawler(Website = "https://fortune.com/", # The webpage to crawl
#crawlUrlfilter = "/the-latest/", # A part of the webpage to start from
#dataUrlfilter = "/the-latest/", # Only crawl URLs that have this pattern
KeywordsFilter = c("enterprise"),
#ExtractXpathPat = "//div/ul[@class='termArchiveContentList']",
no_cores = 2, # Number of cores on your computer used to run function
no_conn = 2, # Number of connections made to webpage on one core
MaxDepth = 1, # How far down the link chain the crawler goes
saveOnDisk = FALSE, # Do not save all files on your computer
Obeyrobots = TRUE, # Do as the robots.txt say
RequestsDelay = 0.5) # Wait a bit between each time calling the webpageFor further information about how to use the Rcrawler package in R, I recommend this excellent YouTube video
The owners of various webpages might wish to give some instructions on how to mindfully use scrapers and crawlers. This means for example not scraping content that they do not want scraped (i.e. because it’s deemed sensitive) or not going too fast when scraping (as it can damage the server).
To find the document with instructions for each webpage, use the format:
https://www.webpage.domain/robots.txt
For example:
https://en.wikipedia.org/robots.txt
https://www.brreg.no/robots.txt
https://www.uutilsynet.no/robots.txt
Paste this into your broswer and you will get something like this:

This tells us, among other things, that if you crawl Wikipedia too fast, you might be blocked, and gives us an overview of some types of software that is blocked from being used.
Another example of using Rcrawler
# Load in package for crawling
library(Rcrawler)
Rcrawler("http://virksommeord.no/", # Webpage we would like to crawl
DIR = "./crawl", # The folder we save the files in
no_cores = 4, # Processors to use
dataUrlfilter = "/tale/", # Subset filter for crawling
RequestsDelay = 2 + abs(rnorm(1))) # Delay so as not to shut dow the webpageul nodes are unordered lists, typically lists formatted as bullet points.↩︎