string <- "A string is a sequence of text."30 Text manipulation
A lot of information is stored in text, be it reports, books, archives, mails, or whatever. This is one of the reasons why analyzing text has become so popular. It opens up a whole new window of opportunities when it comes to managing information and creating insight from it.
When working with text, the stages of the work can loosely be divided into three:
- Text manipulation
- Text preprocessing
- Text tokenization
- Text vectorization
- Text modelling
The first is all about managing and cleaning text to create something that is useful for our purposes. Then, we need to break the text into units and convert it to something the computer can work with - preferably numbers of some sort. At last, there are various modelling techniques we can use to analyze the text. We’ll go through each of these stages in these lectures, showing some basic examples of how to do each step.
Text is unstructured data – there is no pre-defined model for how the computer should distinguish between variables, observations, and so on. The text is not made for the computer to make sense of it, and this means that we often have to do quite a lot of preparatory work on text to make it ready for computer processing.
Text in programming language is often referred to as “strings”. A string is basically a sequence of text. They are always wrapped in "". For example, the vector below is a string.
Strings can be long (pages of documents) or short (a sentence or part of a sentence), and they can contain capital letters, small letters, punctuation, symbols, numbers, emojis, foreign letters, and so on. We need to manage this string variation, or else it will create noise when we analyze the text. There are many ways of doing this in R, we’ll use the stringr package along with some regex. Regex is not an R package. It stands for “regular expression”, and it is a method to specify patterns in text according to the patterns they display.
30.1 String manipulation using regex and stringr
To make everything a bit clearer, let’s start with some really dirty text – the comment section on YouTube. Here, I have simply copied some of the comments from the video when the judge reads the verdict on the dispute between Johnny Depp and Amber Heard. If you’re curious, you can see the video here. I pasted the text into a txt-file and saved it on my computer.
Now, to read this text into R, we can use the package readtext. This package also works on many other document types such as .doc and .pdf, and we can use it on complete folders containing text. This means that if you want to read in many documents at once, just place the documents in one folder and specify this folder in the “folder” argument:
readtext("/path/folder/")
The function readtext gives you a dataframe with two variables called doc_id and text. The doc_id variable has the name of the document, and the text variable contains the contents of the document.
library(readtext)
comments_trial <- readtext("../datafolder/comment_section_depp-heard-trial.txt")
glimpse(comments_trial)Rows: 1
Columns: 2
$ doc_id <chr> "comment_section_depp-heard-trial.txt"
$ text <chr> "\nPinned by CBS News\nCBS News\n4 days ago\nWatch more videos …We fetch the information from the text variable using select and pull. Then, using the function substr, I show the 100 first characters in the string. The text is pretty noisy. We have:
- Big letters and small letters
- URLs
- Line shifts (the symbol for line shift is
\nand\n\n) - Numbers
- Foreign signs such as â and €™.
comments_trial_text <- comments_trial %>%
select(text) %>% # Getting only the text variable
pull() # Making the variable into a single character vector
comments_substring <- substr(comments_trial_text, 1, 100)
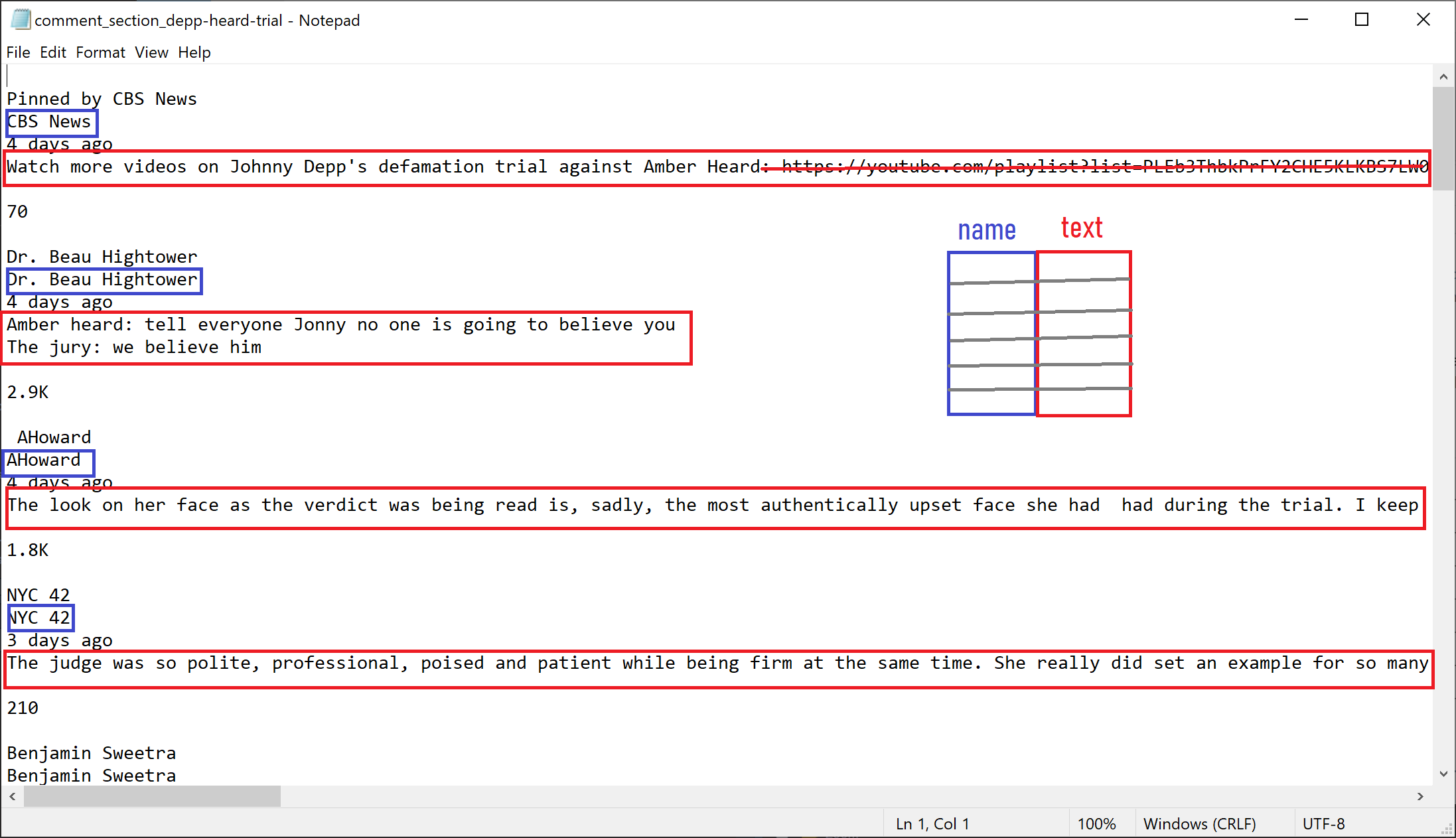
comments_substring # Showing character 1 to 100 of the text.[1] "\nPinned by CBS News\nCBS News\n4 days ago\nWatch more videos on Johnny Depp's defamation trial against "Often, what we want is to clear out the most important parts of the information and move it into a dataframe. We might for example want to fetch the names of who posted a comment and the text from the comment, arranging them in two different columns in a dataframe, as shown in the picture below1. Also, typically we want to remove the parts of the text that is not important for us, for example URLs.
30.2 stringr
stringr is a package within the tidyverse that offers a handful of functions for text manipulation.
substr(comments_substring, 1, 5) # Fetch parts of a string, here characters from position 1 to position 5[1] "\nPinn"str_length(comments_substring) # Check how many characters a present in a string[1] 100str_c(comments_substring, ". The end.") # Put together two strings. (Equivalent to paste and paste0)[1] "\nPinned by CBS News\nCBS News\n4 days ago\nWatch more videos on Johnny Depp's defamation trial against . The end."str_to_upper(comments_substring) # Make all characters into upper case[1] "\nPINNED BY CBS NEWS\nCBS NEWS\n4 DAYS AGO\nWATCH MORE VIDEOS ON JOHNNY DEPP'S DEFAMATION TRIAL AGAINST "str_to_lower(comments_substring) # Make all characters into lower case[1] "\npinned by cbs news\ncbs news\n4 days ago\nwatch more videos on johnny depp's defamation trial against "str_to_title(comments_substring) # Give all words a start capital letter and make the rest lower case[1] "\nPinned By Cbs News\nCbs News\n4 Days Ago\nWatch More Videos On Johnny Depp's Defamation Trial Against "str_to_sentence(comments_substring) # Give all sentences a start capital letter and make the rest lower case[1] "\nPinned by cbs news\nCbs news\n4 days ago\nWatch more videos on johnny depp's defamation trial against "str_detect(comments_substring, "Johnny Depp") # Check if a pattern is part of a string[1] TRUEstr_subset(comments_substring, "Johnny Depp") # Subset the strings that contain a specific pattern[1] "\nPinned by CBS News\nCBS News\n4 days ago\nWatch more videos on Johnny Depp's defamation trial against "str_locate(comments_substring, "Johnny Depp") # Check where in the string a specific pattern is located start end
[1,] 62 72str_extract(comments_substring, "Johnny Depp") # Extract only the part of a string that matches a specific pattern[1] "Johnny Depp"str_remove(comments_substring, "Johnny Depp") # Remove from the string all instances that match a specific pattern[1] "\nPinned by CBS News\nCBS News\n4 days ago\nWatch more videos on 's defamation trial against "str_replace(comments_substring, "Johnny Depp", "Jack Sparrow") # Replace patterns of a string with another string[1] "\nPinned by CBS News\nCBS News\n4 days ago\nWatch more videos on Jack Sparrow's defamation trial against "str_trim(comments_substring) # Remove whitespace from the start and the end of a string[1] "Pinned by CBS News\nCBS News\n4 days ago\nWatch more videos on Johnny Depp's defamation trial against"str_squish(comments_substring) # Remove whitespace from the start and end of a string, and inside a string[1] "Pinned by CBS News CBS News 4 days ago Watch more videos on Johnny Depp's defamation trial against"str_split(comments_substring, "\n") # Make a list of strings by splitting them on a certain pattern[[1]]
[1] ""
[2] "Pinned by CBS News"
[3] "CBS News"
[4] "4 days ago"
[5] "Watch more videos on Johnny Depp's defamation trial against "str_conv(comments_substring, "UTF-8") # Convert the encoding of a string - useful if you get a lot of weird characters in your strings[1] "\nPinned by CBS News\nCBS News\n4 days ago\nWatch more videos on Johnny Depp's defamation trial against "Some of these functions also allow us to add an _all, which would match all instances of a pattern.
str_locate_all()
str_extract_all()
str_remove_all()
str_replace_all()These functions are excellent when working with strings. Yet, notice that they often require a pattern. This pattern can be a string that matches the text perfectly, for example the name “Johnny Depp”. However, if we want to do large-scale cleaning of a text, we should work to find more general patterns, and use these to decide which parts of the string that should be kept, removed, modified, and so on. To specify patterns, we use regex.
30.3 Regex
Regex stands for “Regular expressions”, and it is a method to match patterns in text. This allows us to handle many instances of the same thing in large volumes of text.
To understand what we mean by pattern, consider an email address. Some collections of email addresses can be quite standardized, for example emails within a company. Imagine a company by the name ThreePods with the abbreviation TP and the domain .com, giving all their employees email addresses with their surname. This collection of email addresses might look something like this:
smith@tp.com
johnson@tp.com
brown@tp.com
perez@tp.com
young@tp.com
To match these strings, we can use regex and specify that we want to match all strings that begin with a sequence of characters, followed by an @, then tp and .com. The regex string would look like this:
"[a-z]+@tp.com"
So what would this look like with the stringr functions above? Well, imagine that we have a bunch of text and want to only extract the email addresses. Then we could use str_extract_all (to get all five email addresses, not just one) together with our regex pattern and do this:
text <- "Here in the company ThreePods, we deliver many services of great quality that make important contributions to you and the world around you. Our service team is always ready to help. John Smith is the head of the service team, and can be reacehd at smith@tp.com. Anne Johnson, Bill Brown and Nico Perez, available at johnson@tp.com, brown@tp.com and perez@tp.com, also work tiredlessly to improve efficiency and quality. If you have questions or comments on this piece of text, you can contact me, Amy Young, at young@tp.com."
str_extract_all(text, "[a-z]+@tp.com")[[1]]
[1] "smith@tp.com" "johnson@tp.com" "brown@tp.com" "perez@tp.com"
[5] "young@tp.com" The regex pattern in the string above is the [a-z]+ part. [a-z] means “match any lower case character, and + means that the pattern can include both one or several of these. In other words; match any single or group of lower case characters. The table below shows an overview of some of the regex patterns, along with some examples of how they can be used in practice.
In particular, notice the \. Whenever you in regex want to specify for example that the pattern should contain a question mark, use two times backslash first; \\?.
| Char | Description | Meaning |
|---|---|---|
| \ | Backslash | Used to escape a special character |
| ^ | Caret | Beginning of a string |
| $ | Dollar sign | End of a string |
| . | Period or dot | Matches any single character |
| | | Vertical bar or pipe symbol | Matches previous OR next character/group |
| ? | Question mark | Match zero or one of the previous |
| * | Asterisk or star | Match zero, one or more of the previous |
| + | Plus sign | Match one or more of the previous |
| ( ) | Opening and closing parenthesis | Group characters |
| [ ] | Opening and closing square bracket | Matches a range of characters |
| { } | Opening and closing curly brace | Matches a specified number of occurrences of the previous |
Examples
Finished\? matches “Finished?”
^http matches strings that begin with http
[^0-9] matches any character not 0-9
ing$ matches “exciting” but not “ingenious”
gr.y matches “gray“, “grey”
Red|Yellow matches “Red” or “Yellow”
colou?r matches colour and color
Ah? matches “Al” or “Ah”
Ah* matches “Ahhhhh” or “A”
Ah+ matches “Ah” or “Ahhh” but not “A”
[cbf]ar matches “car“, “bar“, or “far”
[a-zA-Z] matches ascii letters a-z (uppercase and lower case)
30.4 Example: string and regex for comments section cleaning
Lets look at how stringr and regex can be used for cleaning of our comments section string. As mentioned above, a typical problem is that we start with a chunk of text, but what we really want is a dataframe with tidy variables. The job of cleaning text can be very time consuming and nitpicky, and I am not going to delve into the details here. However, here is an example of a code to go from a chunk of text to a dataframe using stringr and regex. The dataframe has two variables - one with who has posted a comment (name) and one with the content of their post (text).
comments <- comments_trial_text %>%
str_split("\n\n") %>% # Split the text on double lineshift, \n\n
.[[1]] %>% # Pick the first element of the list, as we only have one
str_remove_all("[0-9]+(\\.)?(K)?") %>% # Remove all parts of the string containing numbers, possiblu followed by dot and possibly followed by K
str_remove_all("days ago|hours ago|\\(edited\\)|Pinned by") %>% # Removing these strings from the text, as we're not gathering info on the time of the comments
stringi::stri_remove_empty() %>% # Removing all empty character vectors
str_split("\n") %>% # Splitting again on single lineshift
map(., ~ str_squish(.)) %>% # Removing whitespace from between and within the string, using map because we now have a list of lists
map(., ~ stringi::stri_remove_empty(.)) %>% # Removing empty character vectors again
map(., ~ unique(.)) # Picking only the unique values
name <- list() # Make a list where we can store the names
text <- list() # Make a list where we can store the text
for (i in 1:length(comments)) { # Creating a for-loop
name[[i]] <- comments[[i]][1] # Picking the first vector element in every list element and store it in the vector called "name"
text[[i]] <- str_c(comments[[i]][-1], collapse = "") # Picking the rest of the elements from the list elements and collapsing them to a single character vector
}
dataframe <- as_tibble(list(name = unlist(name), # Putting the two vectors together into a dataframe
text = unlist(text)))
dataframe <- dataframe %>%
mutate(text = str_remove_all(text, "https://.*"), # In the dataframe, I change the text variable and remove URLs, that is, all strings starting with https:// followed by anything
text = str_conv(text, "ASCII"), # The text has emojis, to remove them I convert the text to ASCII encoding
text = str_replace_all(text, "\uFFFD", "")) # Now all emojis are called UFFFD, and I remove them
dataframe <- dataframe %>%
mutate(name = ifelse(str_length(name) >= 50, NA, name)) %>% # One text ended up in the name columns, I turn it into NA filtering on strings with more than 50 characters
na.omit() # And remove NA from the dataframe
dataframe# A tibble: 27 × 2
name text
<chr> <chr>
1 CBS News "Watch more videos on Johnny Depp's defamation trial agai…
2 Dr. Beau Hightower "Amber heard: tell everyone Jonny no one is going to beli…
3 AHoward "The look on her face as the verdict was being read is, s…
4 NYC "The judge was so polite, professional, poised and patien…
5 Benjamin Sweetra "This is a big win because it shows we cant automatically…
6 Mary Gaia "Proud of our jury system. They did the job that was entr…
7 Jacy LB "Shes an embarrassment to DV abuse victims. Her statement…
8 Artsy "I honestly didnt think Depp would win because defamation…
9 Welly Sanusi "So happy for Johnny Depp. Through the trial, everyone ca…
10 Kimber Doe "Imagine being someone in this situation who was actually…
# ℹ 17 more rowsIt could also have been useful to extract the time when the comment was made, but it all depends on what kind of analysis you want to do↩︎